CNN Fixations - An unraveling approach to visualize the discriminative image regions
Konda Reddy Mopuri*, Utsav Garg*, R. Venkatesh Babu (*=equal contribution)
Abstract
Deep convolutional neural networks (CNN) have revolutionized various fields of vision research and have seen unprecedented adoption for multiple tasks such as classification, detection, captioning, etc. However, they offer little transparency into their inner workings and are often treated as black boxes that provide excellent performance. In this work, we aim at alleviating this opaqueness of CNNs by providing visual explanations for the network’s predictions. Particularly, for the CNNs trained to perform object recognition, we localize the predicted label on the image in the form of responsible pixel locations. To achieve this, we unravel the forward pass operation by exploiting the feature dependencies across the layer hierarchy and uncover the discriminative image locations that guided the network’s prediction. We name these locations CNN-Fixations, loosely analogous to human eye fixations. Our approach is a generic method that requires no architectural changes, additional training or gradient computation and computes the important image locations (CNN Fixations) from a single forward pass operation. We demonstrate through a variety of applications that our approach is able to localize the discriminative image locations across different network architectures, diverse vision tasks and data modalities.
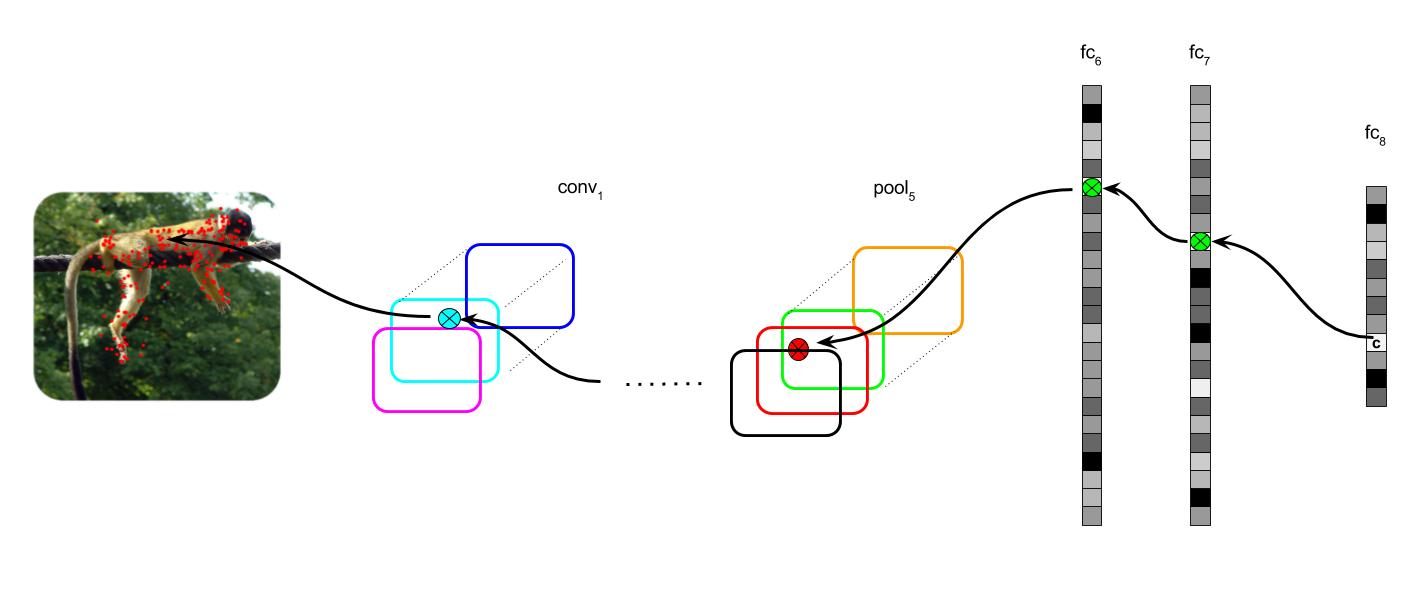
Overview of the approach
Reference
@article{mopuri2017cnn,
title={CNN Fixations: An unraveling approach to visualize the discriminative image regions},
author={Mopuri, Konda Reddy and Garg, Utsav and Radhakrishnan, Venkatesh Babu},
journal={arXiv preprint arXiv:1708.0667},
year={2017}
}